Execution flow
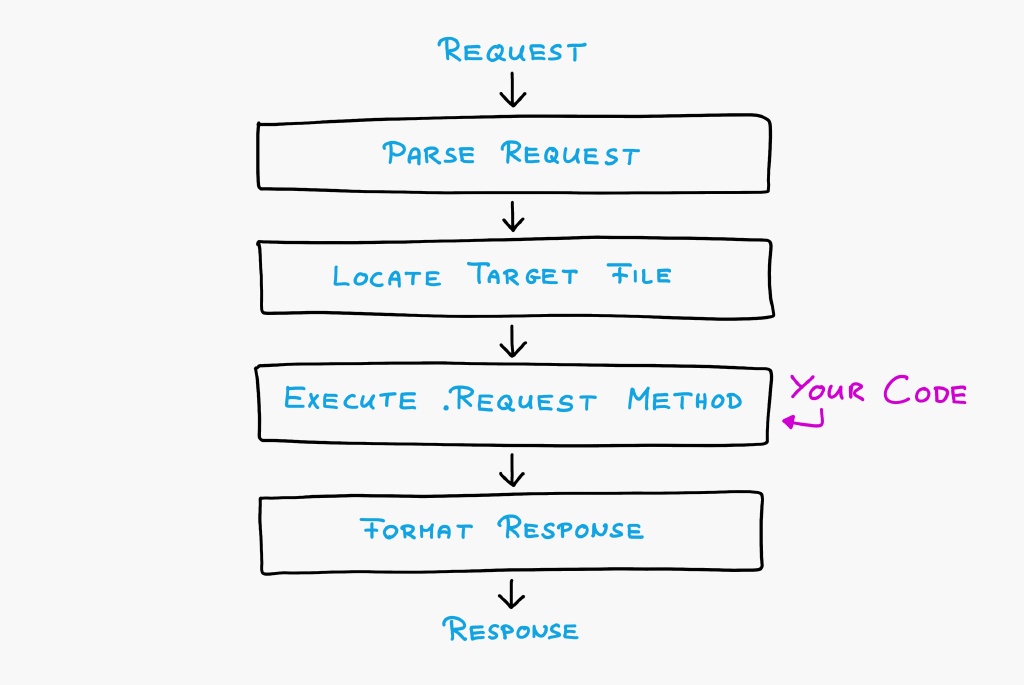
The execution flow of Boomla is both extremely simple and super flexible. The platform takes care of the heavy lifting of parsing the request, authenticating the user, routing the request to the right file on the filesystem, formatting and returning the response and enforcing content security security rules.
All you have to do is write the actual app, that is, the .Request method that will handle the request.
Let's see the execution flow.
Parse Request
This includes parsing the request path, all query GET and POST parameters and any uploaded files.
A virtual request file is created and all the request data is written to this request file. Your application will be able to read this request file to access all the request data.
Locate Target File
If the request was made against the URL https://example.com/foo/bar, then Boomla will try to find the file //example.com/foo/bar.
Every website has its own filesystem. The root file of the website at https://example.com is //example.com (without the http: prefix).
Execute the .Request Method
Boomla is an object-oriented platform. For the purposes of understanding the execution model of Boomla, you should think in terms of objects, not files.
After Boomla has located the target object //example.com/foo/bar, it loads the .Request method on it.
The .Request method is either defined as a separate object at //example.com/foo/bar/.Request, or it is implemented by the application that is associated with the target file.
Which application? Every file (object) has a type property which defines the app responsible for handling that file.
If you know Object Oriented Programming, this is the same concept. There are classes, in our case apps, that have instances, in our case files.
Notice that your application is fully responsible for rendering and returning the page, image, video, whatever. There is no Apache configuration with magic file extensions. To return an image, you can write your own app that returns the raw image data and sets the Content-Type of the response. Of course, the most common file types are provided by the platform.
Either case, there is a virtual response file (object) injected into the execution environment that the application can write.
Format Response
Boomla will then take the generated response file, apply any Content-Security-Policy rules, compress the response if necessary, apply caching rules, set authentication cookies if necessary and return the response, either in one go, or as a stream, in case of video files.
Rendering complex web pages
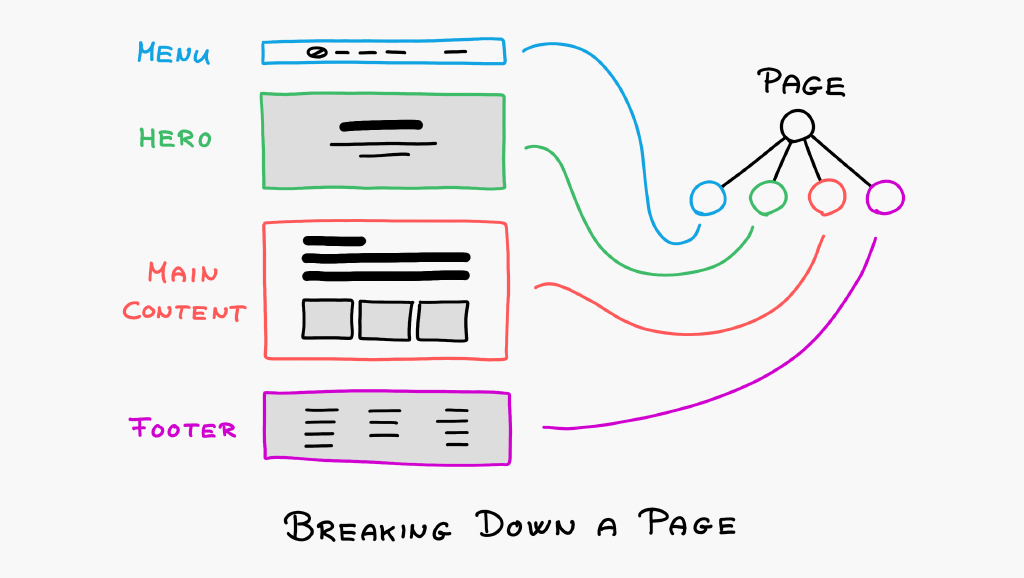
What about complex web pages? What if the page contains a menu, a footer, a big hero element, some text elements and a gallery, like in the following image?

The best practice is to break down the page into conceptual blocks. For example, in the example above, we could store the menu, the big hero element, the main content and the footer in four separate objects, that is, files.
The page would then simply render all four files and concatenate their HTML codes before returning them to the user.
Note that the page file does not need to be aware of the content files that are inside it. It can simply define a bucket, which is like a directory, and then simply find and inline all the files in that bucket. That way, we can develop the page app and the content apps separately.
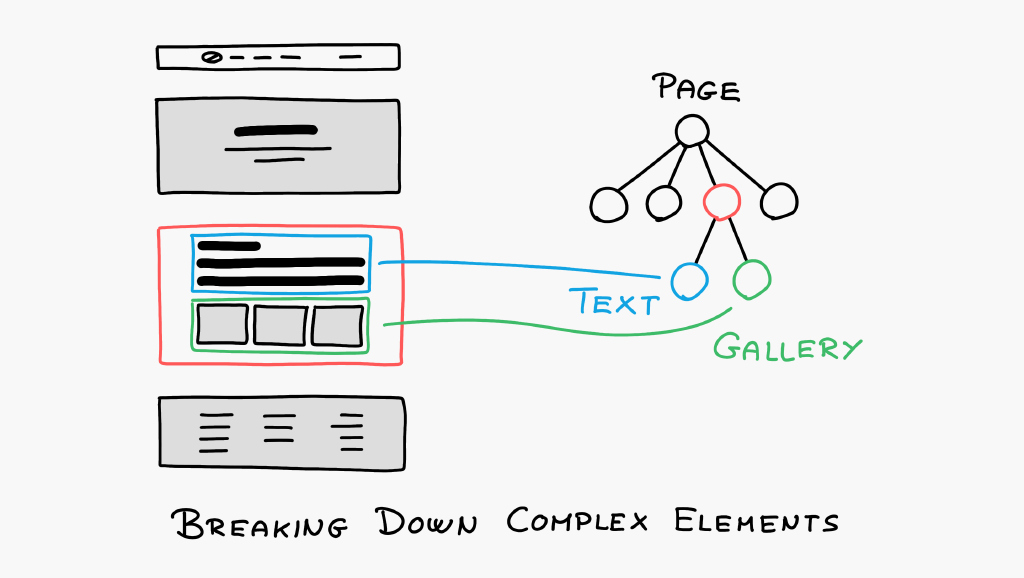
It is also recommended to further break down complex structures like the main content in the example above. It could be decomposed into the layout for the main content area and separate text and gallery elements.
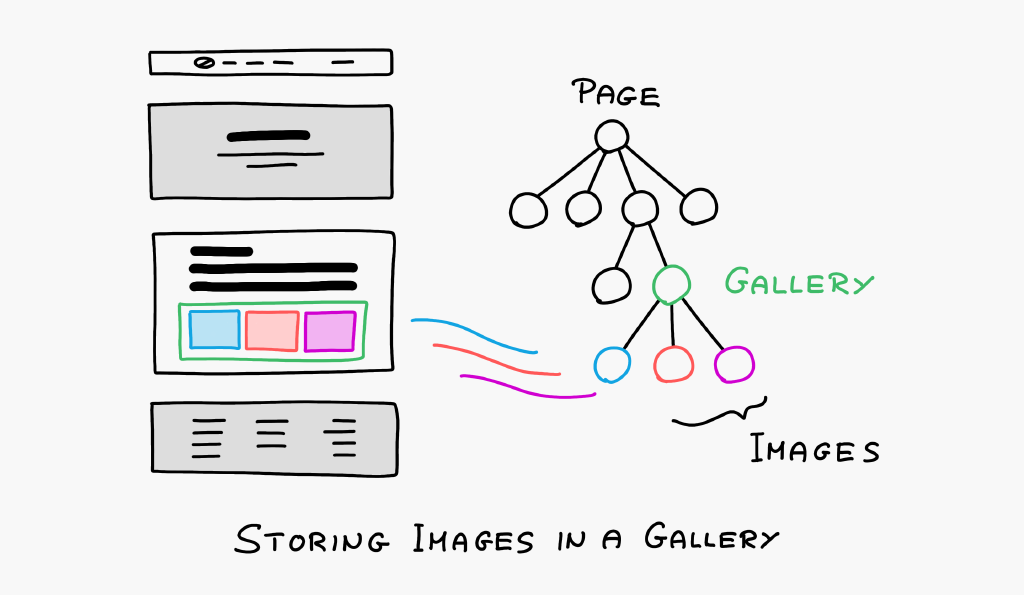
The gallery could store all the images as separate child objects. Then, adding an image to the gallery is as simple as uploading a new image file into the gallery file.
Engines
Each app can define the engine (pre-processor, interpreter, etc.) that shall execute it on the server side. That's crucial, as this allows HTML contents to use simple HMTL code, while more complex apps may define a dynamic programming language that is most suitable for the job. (Currently, only JavaScript is supported.)
The reason the Boomla Filesystem is so different from traditional filesystems is to make this possible.