A filesystem to replace your CMS
2019-10-26
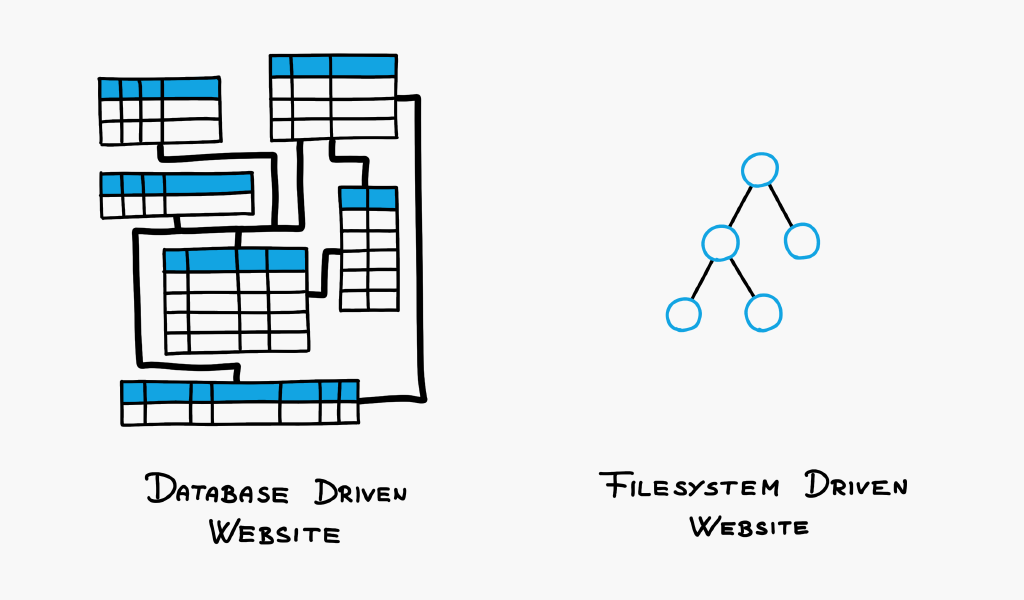
The way Content Management Systems work never made sense to me. I wanted to create an alternative that does. One that you don't have to learn but understand. I figured it all boils down to the data-structure that is used. The smarter the data-structure, the less you have to code. Below, I'm going to show you a new kind of filesystem designed for the problems of web development. Every idea explained below already works. This website runs on it.
Static website
To set the stage: you can upload a static website, it will work without problems.
Break down HTML files
You can move content blocks from the HTML files to separate files and store them as its children. Then, to render the page, we can simply include the children into the parent.

For this to work, our filesystem has to support storing files in files. As in hello.html/heading.html. It's like every file is also a directory at the same time.
Also, files must be stored in order. There is no order_ID field like in databases. The files are actually stored and retrieved in order.
As a benefit, to re-arrange content blocks on a page, you don't need to cut and paste the HTML code. You can simply rearrange the files. You can even copy-paste files across pages. Or duplicate entire pages.
Notice how we replaced database relations, typically IDs, with files' locations. Isn't it beautiful?
Shared page layout
If you do the above, you will likely find that most of your pages have the same layout with a shared menu, header and footer. It is only the page contents that are different.
To solve this, our filesystem supports file types. It's a path pointing to another file defining its behavior. That way, we can centralize our page layout. It's like OOP: we will have something like a page class and page instances. Except the page class is called a page app. I'm not showing any code here to keep this post short. Let's focus on the BIG idea.
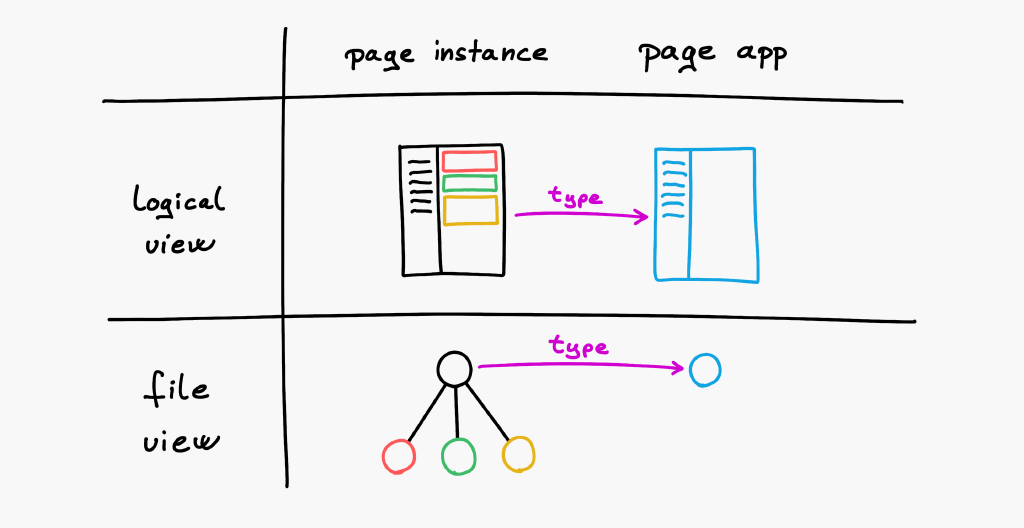
Simply create an empty file and point its type property to the page app, and you have created an empty page!
Gallery
To store images in a gallery, one would create a file for the gallery and store the actual images within that file. From our code, we can simply get the children of the gallery file, and display them as images.
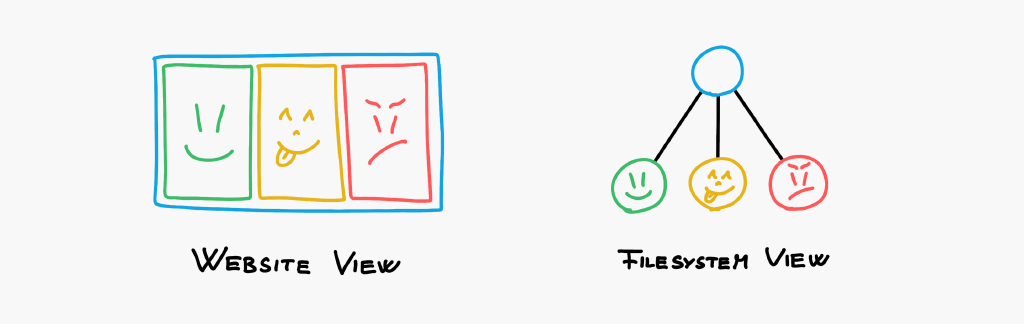
As a benefit, you can simply upload more images into the gallery and they will be displayed automatically! Sort the files to sort the images on the website. There is no cluttered images directory on your server with 1000s of images. If you remove the gallery, the images will also be removed. Automatic clean-up!
Menu
Similarly, the files representing pages form a tree. We can use this tree to generate the menu.
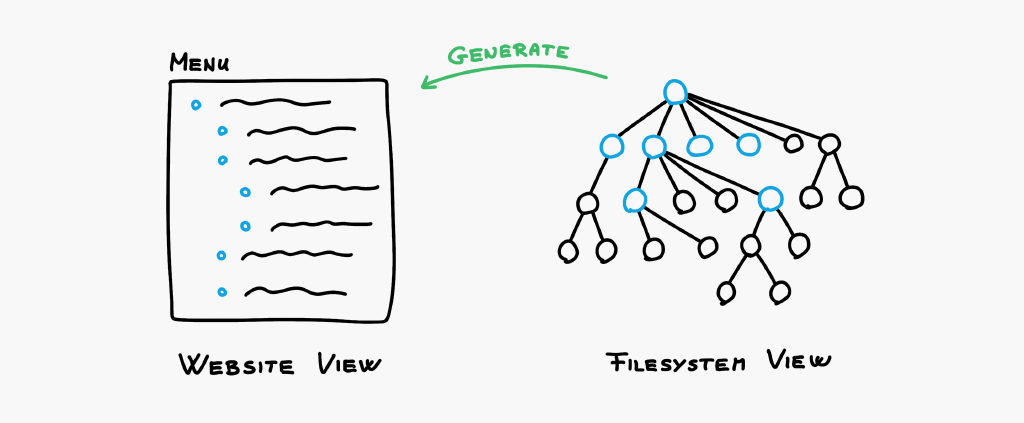
As a benefit, you can easily move around pages on the filesystem, the menu will be automatically updated. You can copy-paste pages. You can rename them.
Drag&drop
Moving around files on the filesystem modifies the structure of the website. You can use drag&drop for that.
One can think of the website as just another view of the filesystem. But then, we can implement drag&drop operations on the website as well by simply mapping them to file operations on the filesystem. I know that most web developers hate drag&drop editors, but this is such an elegant solution.
Maybe drag&drop isn't to blame here, rather the old implementations. Or else, web developers would never use drag&drop to move files on their computers either, right? Come on, don't tell me you never do that..
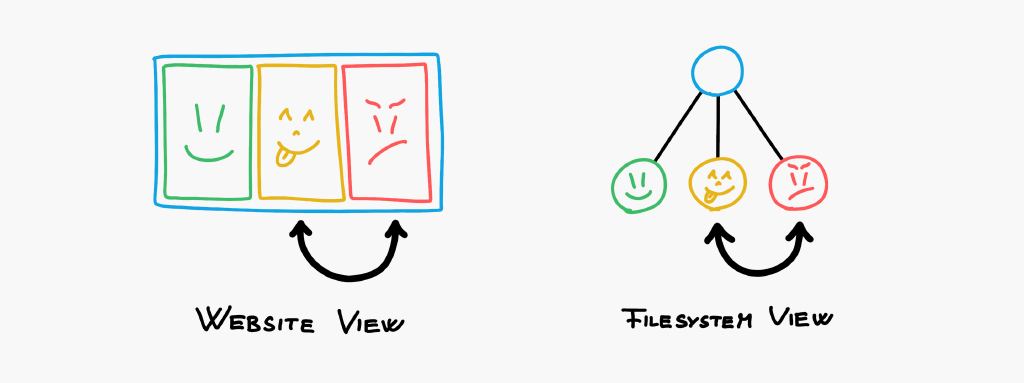
Once we think of them as files, it makes sense to select them, open the contextmenu on them, have copy-paste on the website itself, etc..
Of course, you can also use the command line if you prefer.
File attributes
As we store each element in a separate file, we can also store attributes on that file. For example, we could store the text of a heading element in a file attribute, then inject it into the HTML response upon generating the request. Then we could also add a text editor to allow changing the heading on the website, and upon saving, route it back to the file attribute on the filesystem.
Let me emphasize, the website is stored as a well defined data structure, not as some messy HTML code. The website is simply an interface for editing it. That's no different from having an input field on your admin page.
There is more
Let me mention a couple more features to tickle your interest, but I don't want to explain them in detail here to keep this post short. You also get these out of the box:
it's transactional,
lock-free concurrency (by forking the filesystem),
full-tree integrity checks (stored in merkle trees),
crash recovery (disk is append only, old version is active until new one is on disk),
undo/redo (each filesystem change creates a new filesystem snapshot),
data deduplication (duplicates of a file only use storage space once),
it's fast (indexed in memory similar to databases),
inheritance support (for anything along the type chain),
version control (similar to git but for websites).
How does this replace a CMS?
Typically, Content Management Systems are frameworks that give you a database schema and lots of functions to deal with it. Given this filesystem, you don't need all that. You still need a web server and few other things, but hey, they were never part of your CMS.
How many files does your empty CMS install contain? Boomla contains 1, the website's root file itself. It's so easy to understand the entire codebase, when there is nothing. And it feels great. :)
Importantly, the complexity will remain low due to the functional architecture of the system - but that's leave that to another post.
Use it TODAY
You can use it today as a free, hosted solution. There will be a binary distribution in the future to support offline work as well if there is enough demand and our team gets bigger (currently, it's just me). It existed in the past, I just pulled the plug on it temporarily to move faster.
Right now you can program it in JavaScript through a web based IDE. It will support more languages in the future.
Next
Next, take the developer tutorial and try it in action!
Cheers,