Filesystem and Database are not cutting the problem space right
2020-11-25
This blog post explains the problems with using traditional filesystems and databases for web development and shows a better approach.
The fundamental problem is summarized by the following image:
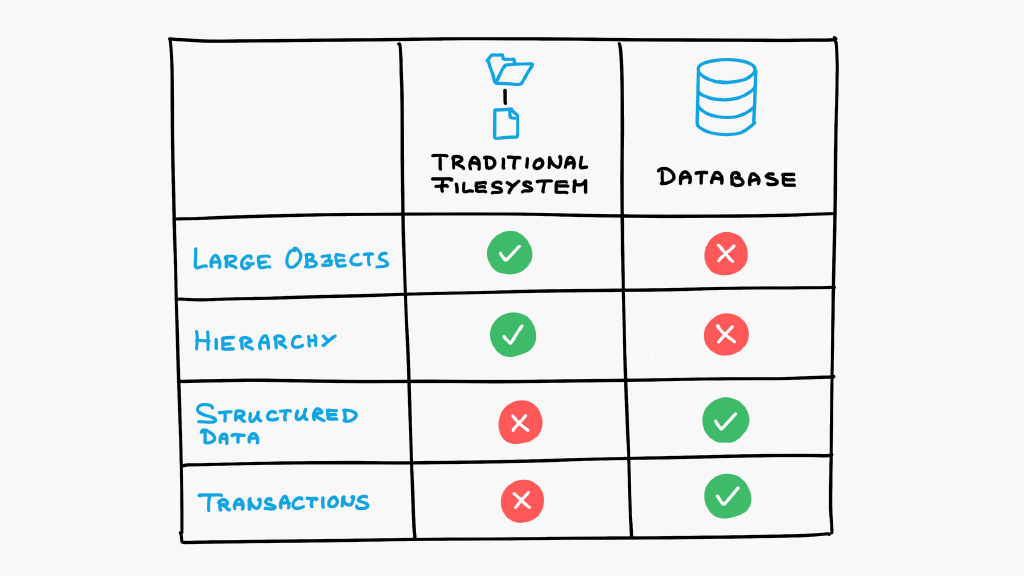
Traditional filesystems and databases have very different properties. Traditional filesystems are best suited for storing large objects while databases for structured data. Traditional filesystems have hierarchy (folders), databases have transactions.
This makes web development way more complex than it should be. Let's look at just one issue.
Where to store user uploaded images?

As we are talking about an image file, it comes natural to store it on the traditional filesystem. Unfortunately, traditional filesystems don't support transactions. Getting the security aspects right is hard. It's a challenge to make consistent backups given that you can't just stop the world. Inevitably, a traditional filesystem will be modified while you are working on the backup. Sooner or later this will cause problems.
Databases can solve all of the above. They have transactions. If you do a backup, it will likely be consistent by default. The problem is, databases are bad with large objects. They are a bad choice if you want to serve lots of users.
This is really frustrating. Why can't we have a storage system that combines the best of both worlds?
I want this:
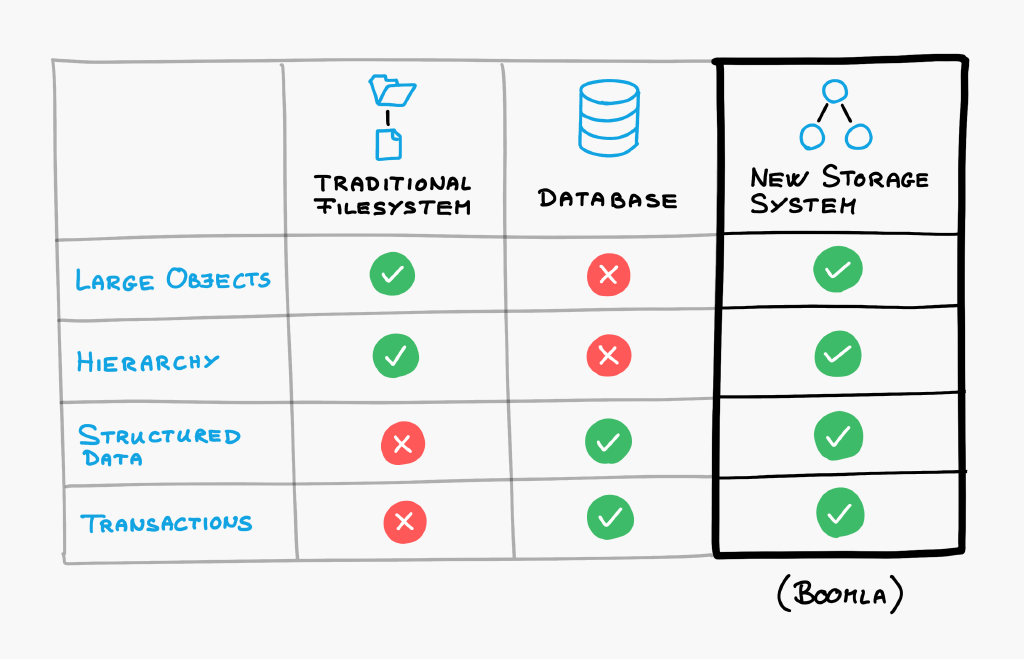
The problem space is cut along the wrong dimensions
Let's take a step back and look at the big picture. This is how the problem space for storing data is currently divided:
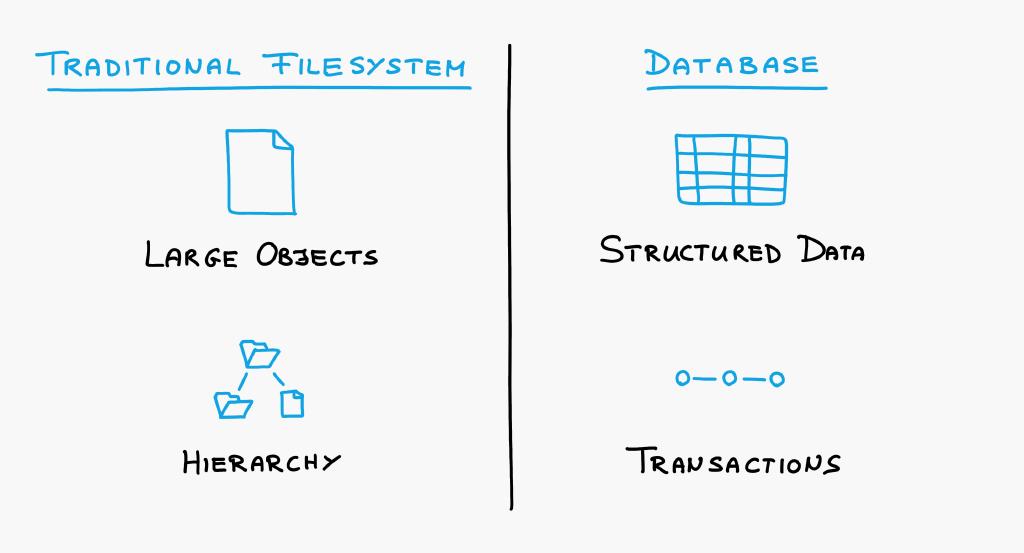
The problem space should be divided along conflicting requirements.
For example, storing ice cream and fruits have conflicting requirements. Ice cream has to be frozen while freezing directly harms fruits. Ice cream requires below zero temperatures while fruits require above zero temperatures. That's a hard conflict. They require different storage solutions.
The thing is, traditional filesystem and database features have no conflicts. Or tell me a single feature that requires:
the lack of hierarchy support,
the lack of large object support,
the lack of transaction support, or
the lack of structured data support.
There is none. Lack of them doesn't add value, it only makes programming harder.
Conflicting requirements
The real conflicting requirements are:
Some changes must be controlled by the owners, while
other changes can not be controlled.
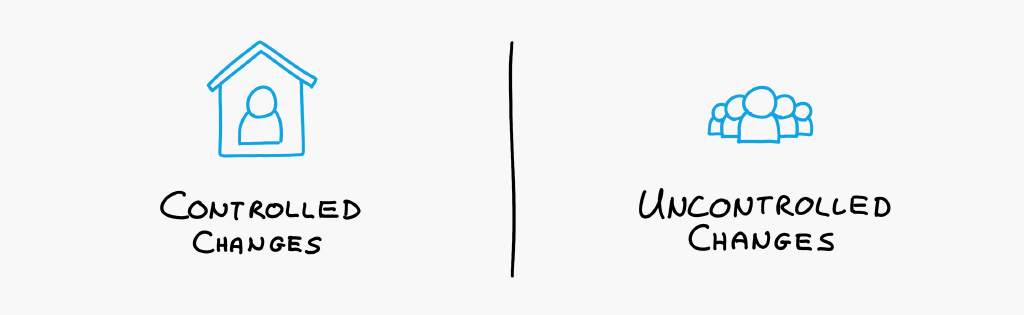
Controlled changes
Some data of the website must be controlled, that is, only changed by the website's owners. This includes the codebase, the page structure, blog post contents, some assets like images and videos or even highly structured data like product features. Such data shall not be changing in the production environment1 as that would mean your visitors see work-in-progress changes that may even break the website temporarily.
Controlled data shall be edited in development environments which shall be clone-able from the production environment. It often requires version control and non-linear development (branching and merging). Upon shipping a new version of the codebase to the production environment, the new state should replace the old state.
Uncontrolled changes
On the other hand, there are changes that simply can not be controlled. This includes user contributions like comments and webshop orders. It includes changes made by automatically executed scripts, for example one that resets counters at midnight. It shall include logs generated while serving requests.
Uncontrolled data consists of linear, sequential changes thus it requires linear snapshots not non-linear feature branches. When cloning the production environment for development purposes, uncontrolled data will typically need to be cloned as well thereby giving you complete freedom to try anything without a complex setup process. This also helps reproducing bugs in minimal time. Upon shipping a new version of the codebase to the production environment, the new state of uncontrolled data shall be typically dropped to prevent accidentally overwriting changes made in production.
The Boomla Filesystem
Most websites and web apps need both a controlled and an uncontrolled storage area. Traditional filesystems and databases are used to store both due to the differences in their capabilities.
Boomla provides a radically simpler web development experience by cutting the problem space along real conflicting requirements, thereby eliminating accidental complexity:
The Boomla Filesystem combines the properties of traditional filesystems and databases.
Boomla provides separate filesystems based on different storage requirements, one for controlled changes and one for uncontrolled changes.
Unified storage
The Boomla Filesystem has a tree structure like a traditional filesystem having files. As expected, Boomla files can store large objects, like images and videos. To store structured data, Boomla files have file attributes to store custom anything in a key-value format, similar to database rows having fields. Finally, the Boomla Filesystem is transactional.
If you are interested in learning more, see the Anatomy of the Boomla Filesystem.
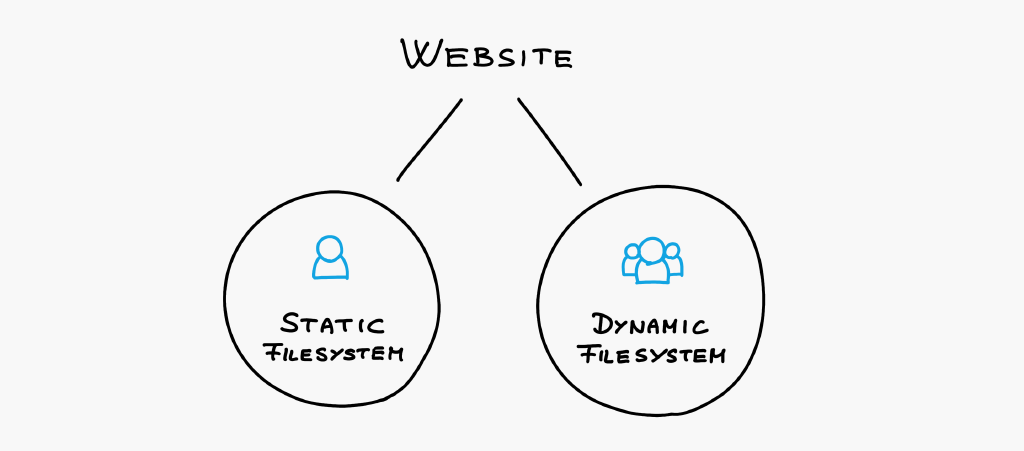
The two Filesystems
Every website contains two filesystem trees as explained above.
The Static Filesystem is the controlled filesystem, and
the Dynamic Filesystem is the uncontrolled filesystem.
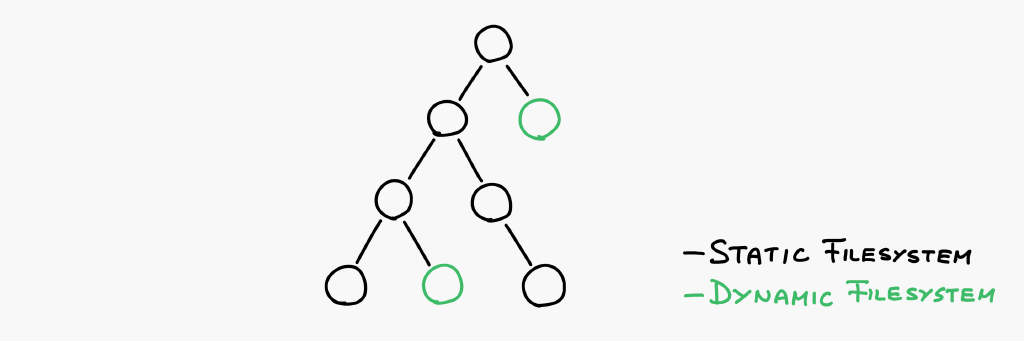
Eliminating global data
We have addressed how to have a hierarchy of objects everywhere, even on the dynamic filesystem but if we store it as a separate filesystem tree, we are back to square one: a global shared namespace. Instead, what we need is the ability to attach dynamic volumes anywhere on the static filesystem, like so:
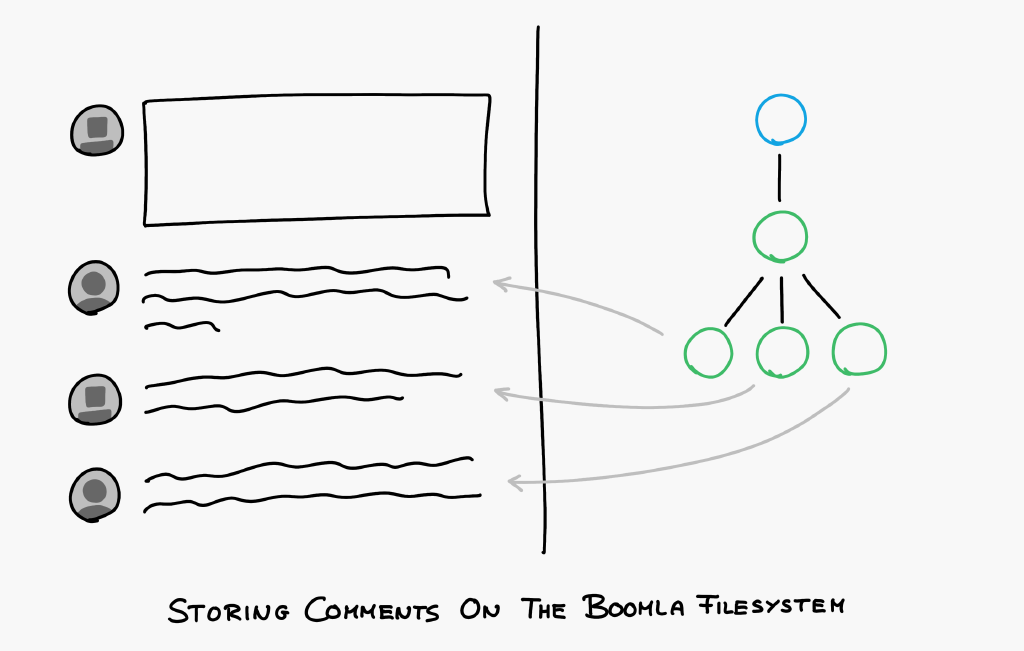
The existence of these dynamic volumes must be version controlled but their contents must not be as they are constantly changing. They must be somehow stored on the dynamic filesystem instead.
Let's see an example. Imagine a comments element embedded into a page. It shall have its own dynamic volume with its own schema. The existence of the comments element must be version controlled but not the actual comments. They can't be: they would cause continuous merging issues.
Removing either the comments element itself (or even the page it is embedded in) must remove the comments element itself with all associated user comments. In the traditional setup, you would have to write lots of code yourself to figure out what data needs to be removed. This takes time (money) and may be non-trivial when there are several 3rd party plugins installed. With proper encapsulation, the system can automatically do this for you.
So here is how this works. Boomla files have a link property. You can attach a dynamic volume anywhere on your website's filesystem by simply setting the file's link property to dynamic.
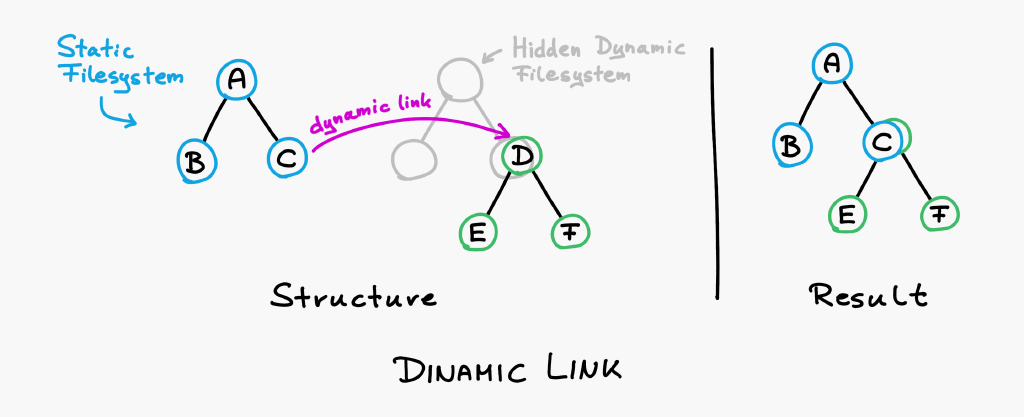
By doing so, the system will create a new volume on the hidden dynamic filesystem and map it to the linking file. (Using the linking file's file ID.) From that point on, you will be able to write the dynamic subtree as usual. It will appear as if it was part of your website's filesystem tree.
That way, in Boomla, deleting the page holding the comments will also remove the actual comments.
The root volume of the dynamic filesystem is hidden by design, it's not directly accessible. If you are interested, see the dynamic link docs for more details.
Undo, redo
One of the really powerful features of the Boomla Filesystem is that undo/redo is available for the entire website. It makes us experiment. We can try things, we can fail and we can always undo. It's a huge boost to dare to try.
The great news is, undo/redo will still be available when collaboration is enabled.
There is a little caveat though. In the production environment you may have multiple users making changes. You definitely don't want to accidentally undo a comment or an order made by someone else. Plus in production, the static filesystem is read-only as you probably don't want your visitors to see your work-in-progress. Because of this, undo/redo is not available in the production environment (master branch).
Once you clone the production environment and thus create a development branch, undo/redo will be available for your entire website. Changes made to the static and dynamic filesystems are bundled in a single atomic transaction, creating a single undo point. That way, whatever changes you make, you will be able to use undo/redo.
To rephrase, you either don't have undo/redo at all (master branch) or you have undo/redo for your entire website (secondary branches).
Users, Access Control, Security
Using a traditional filesystem and database poses another problem with access control.
Access control can only be enforced in a layer that has access to both users and data. It's just impossible otherwise. Websites and web apps introduce their own user concepts. As a result, they should take over all access control responsibilities. Data access should only happen through a single, well defined layer.
Unfortunately, that didn't happen. Both databases and the underlying OS have their own user concepts with their own means of doing access control. Plus your chosen CMS or framework has its own user concept and access control mechanisms. Application developers have access to all of them. They have to call all the right functions themselves to make sure everything is secure. Every application developer has to be a security expert and not make mistakes.
If you are wondering how this could possibly be secure - don't worry, it isn't. It's a complete disaster. (Pro tip: make your competitors use this.)
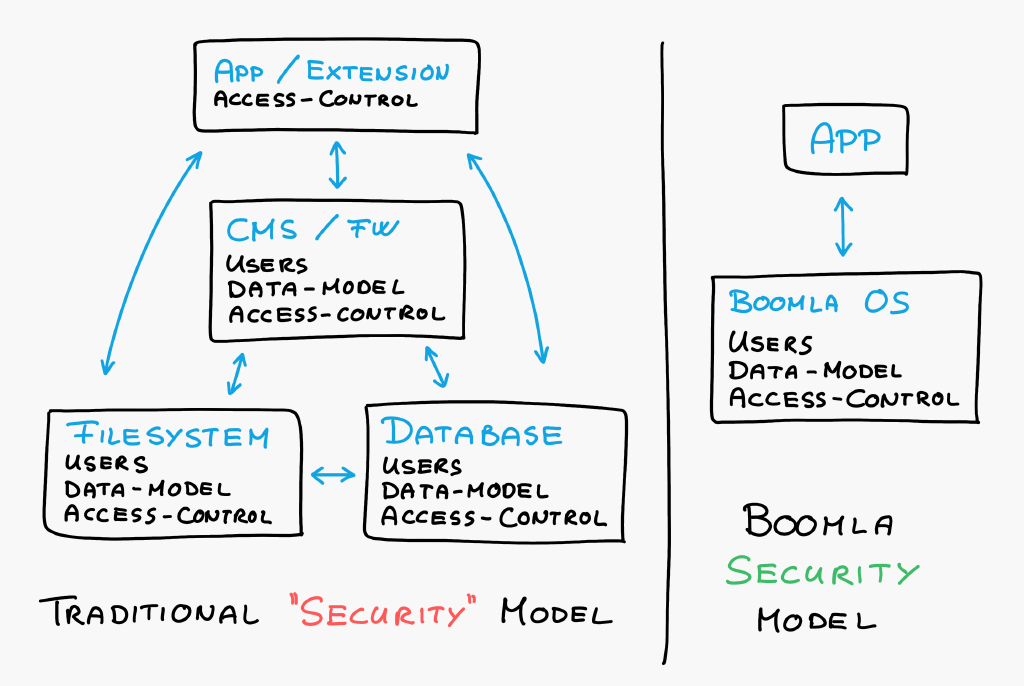
By providing a single storage solution in a single layer with website users, Boomla can do access control centrally. Most importantly, it can be enforced so application developers don't need to do extra work to get it right. They don't need to be security experts.
Additionally, this new approach for separating data into static and dynamic filesystems gives us new opportunities at enforcing security. The static filesystem can be read-only in production, preventing malware from injecting any code. At the same time, we can prevent code execution on the dynamic filesystem as it is a non-trusted storage area. As we are using a filesystem not a database, SQL-injection type attacks are also eliminated.
Workflows
Two different workflows are available:
The Static workflow, and
the Collaborative workflow.
Static workflow
The static workflow does not allow collaboration, you can not attach dynamic volumes to your static filesystem.
On the other hand, the master branch (production environment) of your website will be writable and undo/redo will be available. That's the old workflow thus we will keep it to not disrupt existing users/websites.
Collaborative workflow
To use the dynamic filesystem, you will have to enable the collaborative workflow. Let's see how it's different.
Say you want to implement a new feature or add a new blog post. You can't do that on the master branch (production environment) so you will create a new development branch. You do this by cloning your master branch which includes both the static filesystem and the dynamic filesystem. That way, you have complete freedom to try anything. If you spot a bug on the live website, it will still be there after creating a feature branch. The only change will be that you are now in a safe playground.
It's like cloning your website also cloned your database.
Note that cloning is both free and instant in Boomla due to data deduplication.
Once you are done and happy with your changes, you can publish the static filesystem of your development branch. The dynamic filesystem will not be published, it will be dropped. That way, you are free to implement a new shopping cart system and even test drive it a couple of times without worrying that your changes will affect the live inventory.
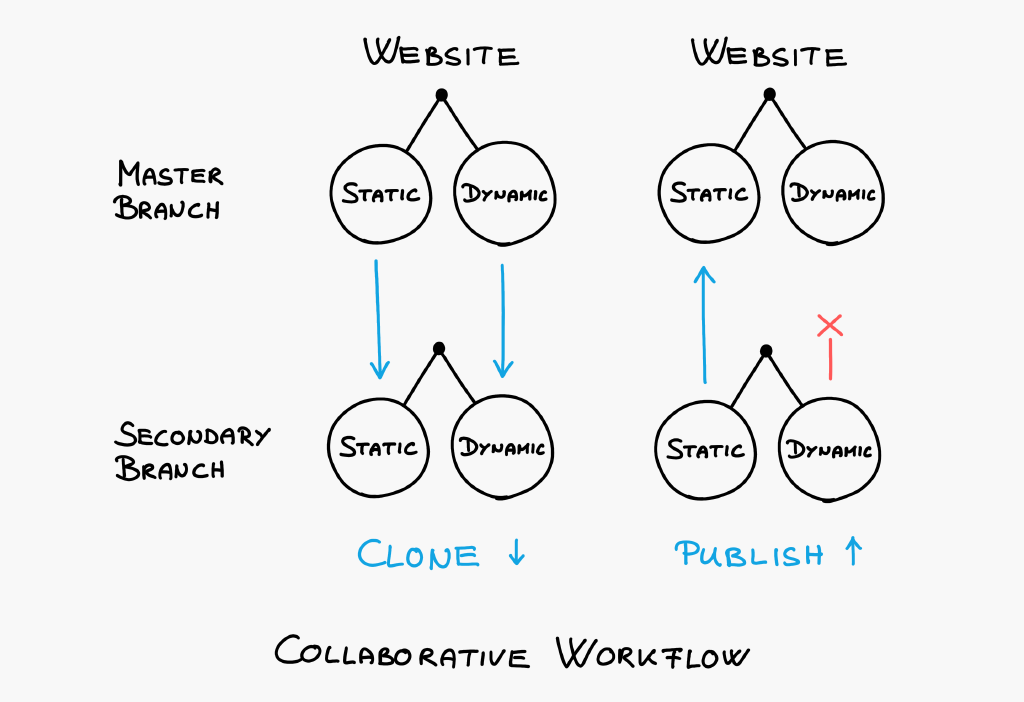
Today, many developers end up with the worst possible setup: only have a production database and run migration scripts directly on that. That's because the current tools we have to live with make it way more complex to set up a full clone environment than it should be.
Stability, Pricing
The Dynamic Filesystem is currently in public beta. We will still need to figure out how to price it as using it will result in more resource hungry websites.
Summary
Traditional filesystems and databases are cutting the problem space along the wrong dimensions, introducing lots of accidental complexity, breaking security and making web development a lot harder than it should be.
The problem space should be cut along conflicting requirements. In the case of web development, this doesn't mean storage system features but the requirement for controlled changes: some data must be controlled while other data simply can not be.
A clean approach simplifies web development and greatly improves security.
Try it in action
I'm working on a tutorial with several examples on how this approach can be used to create simple collaborative applications. For example, how to store comments, user votes and session data.
Subscribe to the newsletter at the bottom of this page if you want to be notified about it.
Closing words
Boomla is a stable, production ready web development platform as a service. You can follow the project on Twitter or subscribe to the newsletter at the bottom of this page. You can also just sign up and explore it. There is lots of documentation including onboarding videos. I'm also happy to help, feel free to reach out!
Many thanks to Shalabh Chaturvedi for reviewing this post.
Cheers,
1) production environment: the public version of your website, also called the master branch. Typically, it is accessible on a domain like example.com or www.example.com. The other environments are called secondary branches or development branches.